Downloading Extracted Features
See the different ways you can download EF files to your local machine or inside a data capsule.
The basics
Rsync
Extracted Features are downloaded using a file transfer utility called rsync, which is a command line utility. Rsync will synchronize files from our servers to your system.
- For Mac or Linux users, rsync should be installed already on your system.
- Windows users can use it through cwRsync - Rsync for Windows or Cygwin.
Tips
- Not including a path will sync all files: this is possible, but remember that (for Extracted Features 2.0) the full dataset is 4 Terabytes! Only download all of it if you know what you are doing. Most people are downloading a subset of the files.
- The fastest way to sync is by pointing at exactly the files that you want. Use the htrc-ef-all-files.txt file if you want the paths to all the EF files.
- Have a custom list of volumes and want to get the file paths for it? We have created two options to help:
- Uploading the volume list to HTRC Analytics as a workset allows you to download a shell script. Details.
- The HTRC Feature Reader installs a command line utility, htid2rsync, and Python functions for doing the same. Details.
HTRC Feature Reader
We provide a Python library called the HTRC Feature Reader which simplifies many of the activities that you may want to perform with EF Dataset, including generating file paths for volumes for which you know the HathiTrust volume ID. The Feature Reader is compatible with Extracted Features versions 2.0 and 1.5.
Read full documentation for the HTRC Feature Reader, including code examples.
File names
Filenames are derived from the associated volume's HathiTrust volume ID, with the following characters substituted:
| original character | substitute character |
|---|---|
| : | + |
| / | = |
Unzipping downloaded files
The downloaded content will be compiled in a compressed file (.bz2). You will need to navigate your local system and properly unzip any file(s) you wish you view. The bunzip2 command may be useful. Many researchers will prefer to use the compressed files, and the HTRC Feature Reader will work with compressed files.
Download Extracted Features version 2.0
Download Format
File Format
Sample Files
A sample of 100 extracted feature files is available for download through your browser: sample-EF202003.zip
Also, thematic collections are available to download: DocSouth_sample_EF202003.zip (82 volumes), EEBO_sample_EF202003.zip (234 volumes), ECCO_sample_EF202003.zip (412 volumes).
Filepaths
The dataset is stored in a directory specification created by HTRC called stubbytree. (Note: This is a change from previous versions of the Extracted Features dataset that used the pairtree directory specification.) Stubbytree places files in a directory structure based on the file name, with the highest level directory being the HathiTrust source code (i.e. volume ID prefix), and then using every third character of the cleaned volume ID, starting with the first, to create a sub-directory. For example the Extracted Features file for the volume with HathiTrust ID nyp.33433070251792 would be located at:
root/nyp/33759/nyp.33433070251792.json.bz2
Download Options
Rsync
The rsync module (or alias path) for Extracted Features 2.0 is data.analytics.hathitrust.org::features-2020.03/ .
If you run the rsync command as written above, without specifying file paths, it will sync all files. Do not do this unless you are prepared to work with the full dataset, which is 4 TB. Make sure to include the final period (.) when running your command in order to sync the files to your current directory, or else provide the path to the local directory of your choosing where you would like the files to be synced to.
A full listing of all the files is available from:
rsync -azv data.analytics.hathitrust.org::features-2020.03/listing/file_listing.txt
It is possible to sync any single Extracted Features file in the following manner:
rsync -av data.analytics.hathitrust.org::features-2020.03/{PATH-TO-FILE} .
Rather than learning the pairtree specification, we recommend using the HTRC Feature Reader’s command line htid2rsync tool. For example, to get rsync a single Extracted Features file when you know the HathiTrust volume ID:
htid2rsync {VOLUMEID} | rsync --files-from - data.analytics.hathitrust.org::features-2020.03/
You can also download multiple files by writing the Extracted Features files’ paths to a text file, and then run the following command:
rsync -av --files-from FILE.TXT data.analytics.hathitrust.org::features-2020.03/ .
You can sync into a single folder, throwing away the directory structure, by adding --no-relative to the rsync command:
rsync -av --no-relative --files-from FILE.TXT data.analytics.hathitrust.org::features-2020.03/ .
Converting HathiTrust Volume ID to stubbytree URL using HTRC Feature Reader
If you already have a list of HT volume IDs, you can use a Python library developed by the HTRC called the HTRC Feature Reader library, to prepare to rsync your volumes of interest. Here is an example showing the conversion of one HT volume ID into an rsync url as it would incorporated into Python:
from htrc_features import utils
utils.id_to_rsync('hvd.32044140344292') # 'format' is an optional parameter with the default value of format=’stubbytree’
Feature Reader also comes with a command line utility called htid2rsync which can be used to generate filepaths to EF 2.0 data:
>>$ htid2rsync hvd.32044140344292 >> hvd/34449/hvd.32044140344292.json.bz2
Use HTRC EF Download Helper Algorithm
To download the Extracted Features data for a specific workset in HTRC Analytics, there is an algorithm that generates the Rsync download script, the Extracted Features Download Helper. The tool can also be useful if you don’t want to go through the process of determining files paths. Select version 0.2 when you run the algorithm to get the Extracted Features 2.0 version of the files.
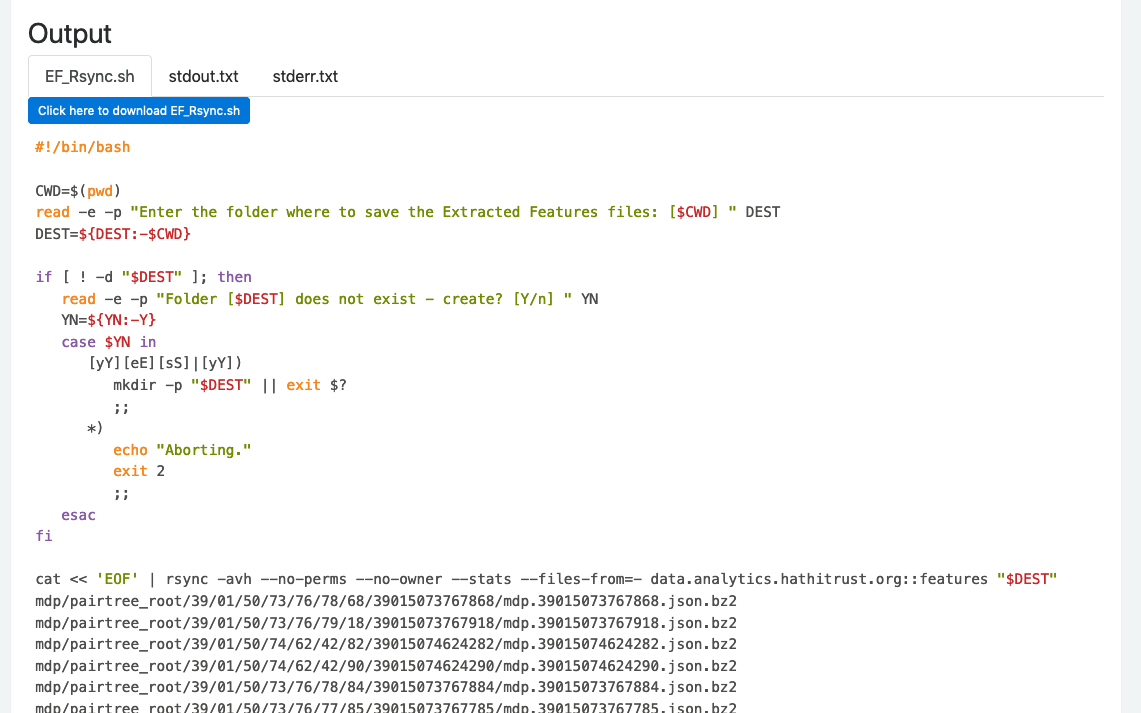
The algorithm creates a shell script that you can download and run from your local command line. The file lists the rsync commands for every volume in an HTRC workset.
The algorithm creates a shell script that you can download and run from your local command line. The file lists the rsync commands for every volume in an HTRC workset. Once you have run the algorithm and downloaded the resulting file, you will run the resulting .sh file.
Go to HTRC Analytics
Navigate to https://analytics.hathitrust.org and log in.
Go to the Worksets page of HTRC Analytics
Click on the 'Worksets' link near the top of the screen. From the list of worksets that appear, choose the one you would like to get Extracted Features for and click on its name.
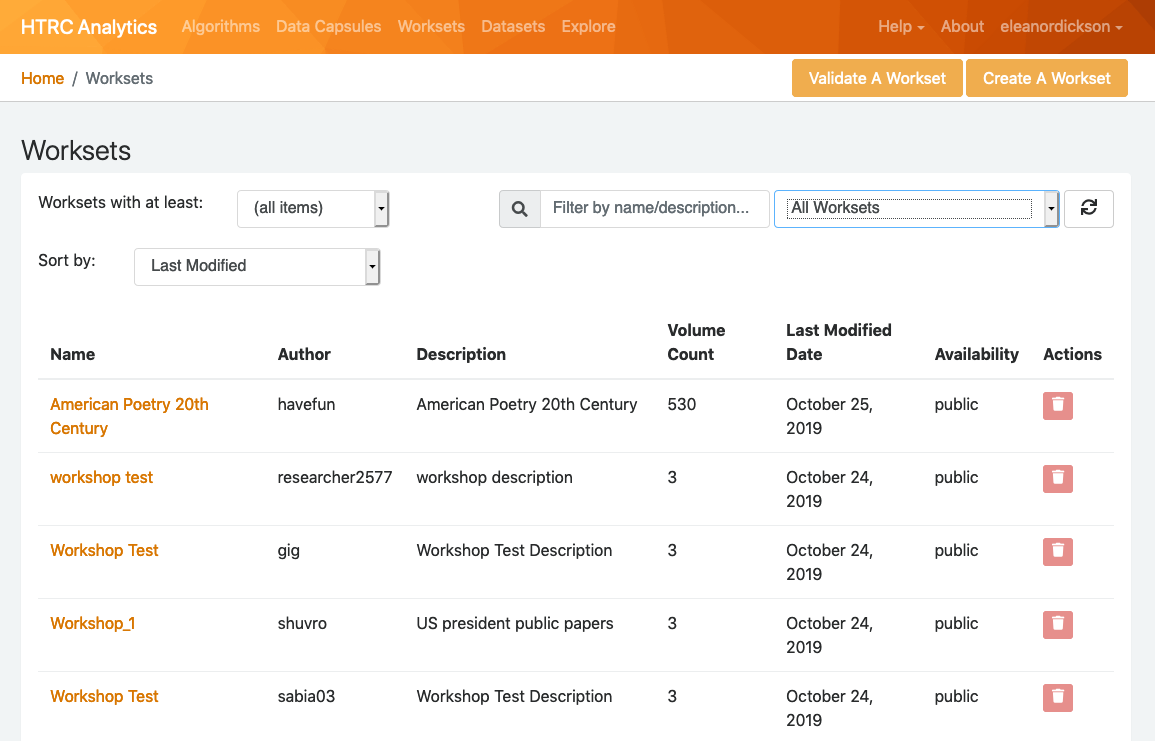
From the 'Analyze with Algorithm' drop down menu, choose the Extracted Features Download Helper algorithm.
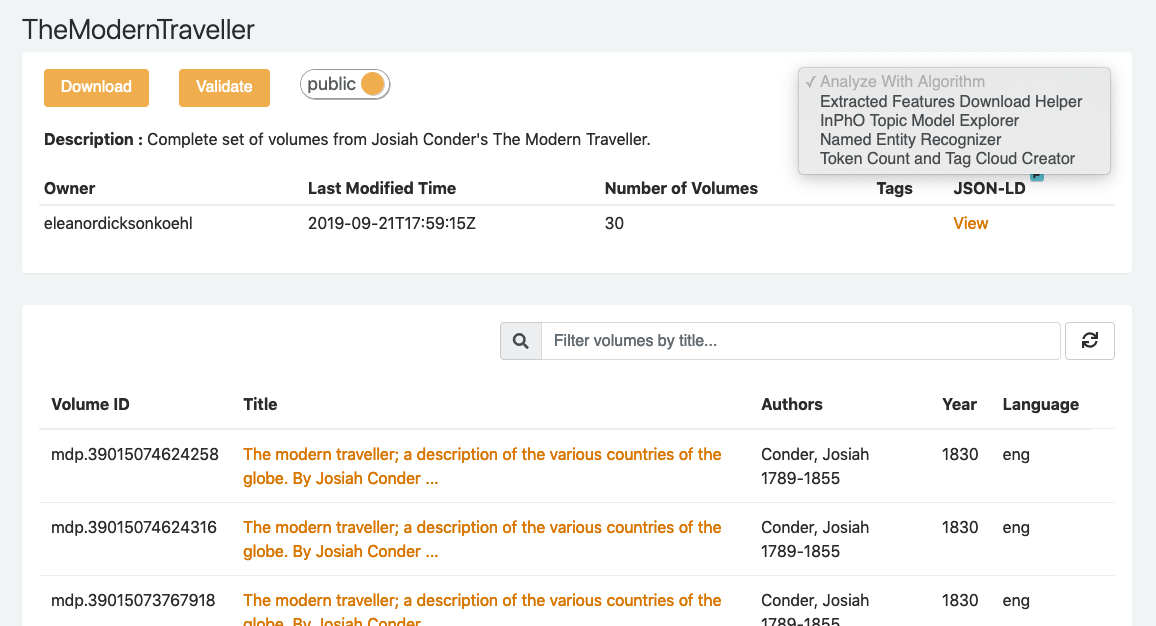
This algorithm generates a script for downloading the feature data files that correspond to your workset.
Execute the Extracted Features Download Helper algorithm
Specify a job name of your choosing. Select Extracted Features 2.0 from the dataset drop down. Then, click the ‘Submit’ button.
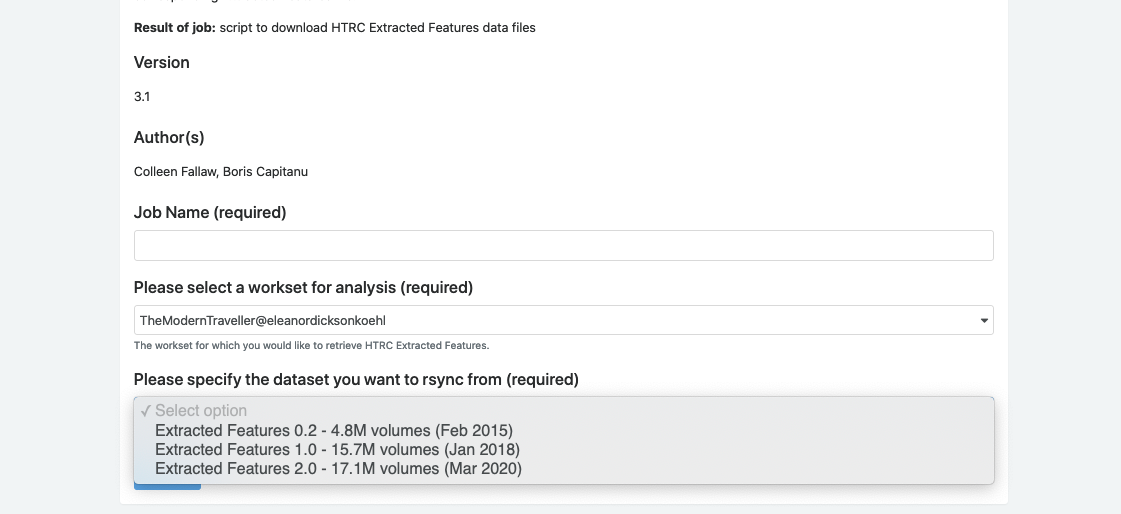
Wait until the algorithm has finished and then open the completed job to download
Eventually, the job will complete, and it will move to the "Completed Jobs" section of the page. Click on the link representing the job name to see the results.
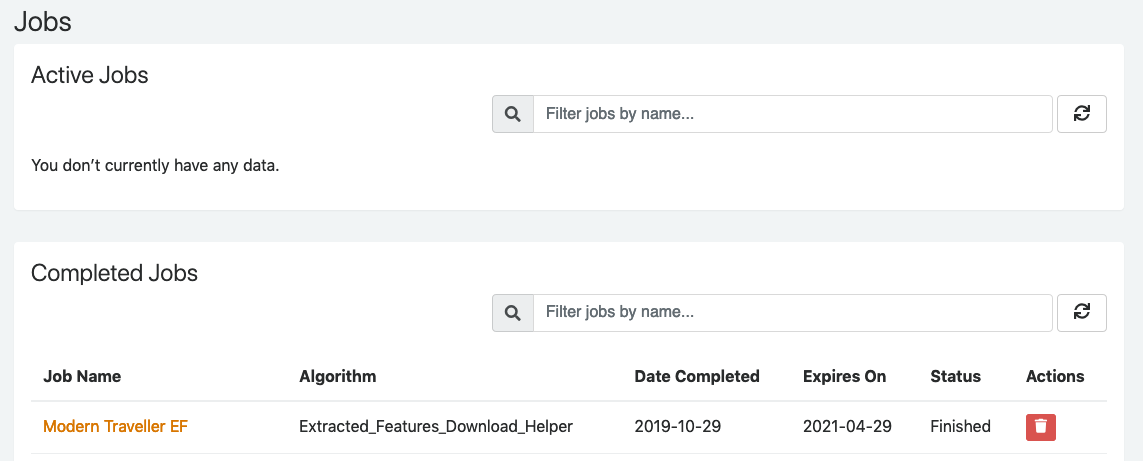
From the results page, click the blue button to download the shell script you will use to get the Extracted Features. The file will go wherever downloads typically end up on your machine, often the Downloads folder.
Downloading Extracted Features version 1.5
Download Format
File Format
/wiki/spaces/DEV/pages/43125245
Sample Files
A sample of 100 extracted feature files is available for download through your browser: sample-EF201801.zip.
Also, thematic collections are available to download: DocSouth_sample_EF201801.zip (87 volumes),EEBO_sample_EF201801.zip (355 volumes), ECCO_sample_EF201801.zip (505 volumes).
Filepaths
The data is stored in a pairtree directory structure, allowing you to infer the location of any file based on its HathiTrust volume identifier. Pairtree format is an efficient directory structure, which is important for HathiTrust-scale data, where the files are placed in directories based on “pairs” of characters in their file names. For example the Extracted Features file for the volume with HathiTrust ID mdp.39015073767769 would be located at:
mdp/pairtreeroot/39/01/50/73/76/69/39015073767769
When you download the files, they will sync in pairtree directory structure, as well.
Download Options
Rsync
The Rsync module (or alias path) for Extracted Features 1.5 is data.analytics.hathitrust.org::features-2018.01/ .
If you run the rsync command as written above, without specifying file paths, it will sync all files. Do not do this unless you are prepared to work with the full dataset, which is 4 TB. Make sure to include the final period (.) when running your command in order to sync the files to your current directory, or else provide the path to the local directory of your choosing where you would like the files to be synced to.
A full listing of all the files is available from:
rsync -azv data.analytics.hathitrust.org::features-2018.01/listing/file_listing.txt
In order to rsync a file or set of files, you must know their directory path on HTRC’s servers. It is possible to sync any single Extracted Features file in the following manner:
rsync -av data.analytics.hathitrust.org::features-2018.01/{PATH-TO-FILE} .
Rather than learning the pairtree specification, we recommend using the HTRC Feature Reader’s command line htid2rsync tool. For example, to get rsync a single Extracted Features file when you know the HathiTrust volume ID:
htid2rsync {VOLUMEID} | rsync --files-from - data.analytics.hathitrust.org::features-2018.01/
You can also download multiple files by writing the Extracted Features files’ paths to a text file, and then run the following command:
rsync -av --files-from FILE.TXT data.analytics.hathitrust.org::features-2018.01/ .
You can sync into a single folder, throwing away the directory structure, by adding --no-relative to the rsync command:
rsync -av --no-relative --files-from FILE.TXT data.analytics.hathitrust.org::features-2018.01/ .
Converting HathiTrust Volume ID to rsync URL using HTRC Feature Reader
If you already have a list of HT volume IDs, you can use a Python library developed by the HTRC called the HTRC Feature Reader library, to prepare to rsync your volumes of interest. Here is an example showing the conversion of one HT volume ID into an rsync url:
from htrc_features import utils
utils.id_to_rsync('hvd.32044140344292', format='pairtree')
Feature Reader also comes with a command line utility called htid2rsync which can be used to generate filepaths to EF 1.5 data using the flag --oldstyle:
>>$ htid2rsync hvd.32044140344292 --oldstyle >> hvd/pairtree_root/32/04/41/40/34/42/92/32044140344292/hvd.32044140344292.json.bz2
Workset Builder 2.0
Extracted Features 1.5 files can also be downloaded for search results in HTRC's beta Workset Builder 2.0. After completing your search, you can download either the Extracted Features files for your results set or for single files from your results.
First, enter search terms for a desired set of volumes. Once results are returned, filter the results to remove any volumes for which you do not want Extracted Features files or to find the volume(s) most relevant to your work.
You can download the files for your entire results set. Once your results includes all of the volumes you'd like Extracted Features files for, click "JSON Extracted Features (ZIP)" under the "Export Search Results" heading at the top of the left sidebar. Clicking this link will start a download of the Extracted Features files for all volumes in your results. Since this process is fetching and compressing files, and result sets can be large, it may take a few moments to start and finish your download.
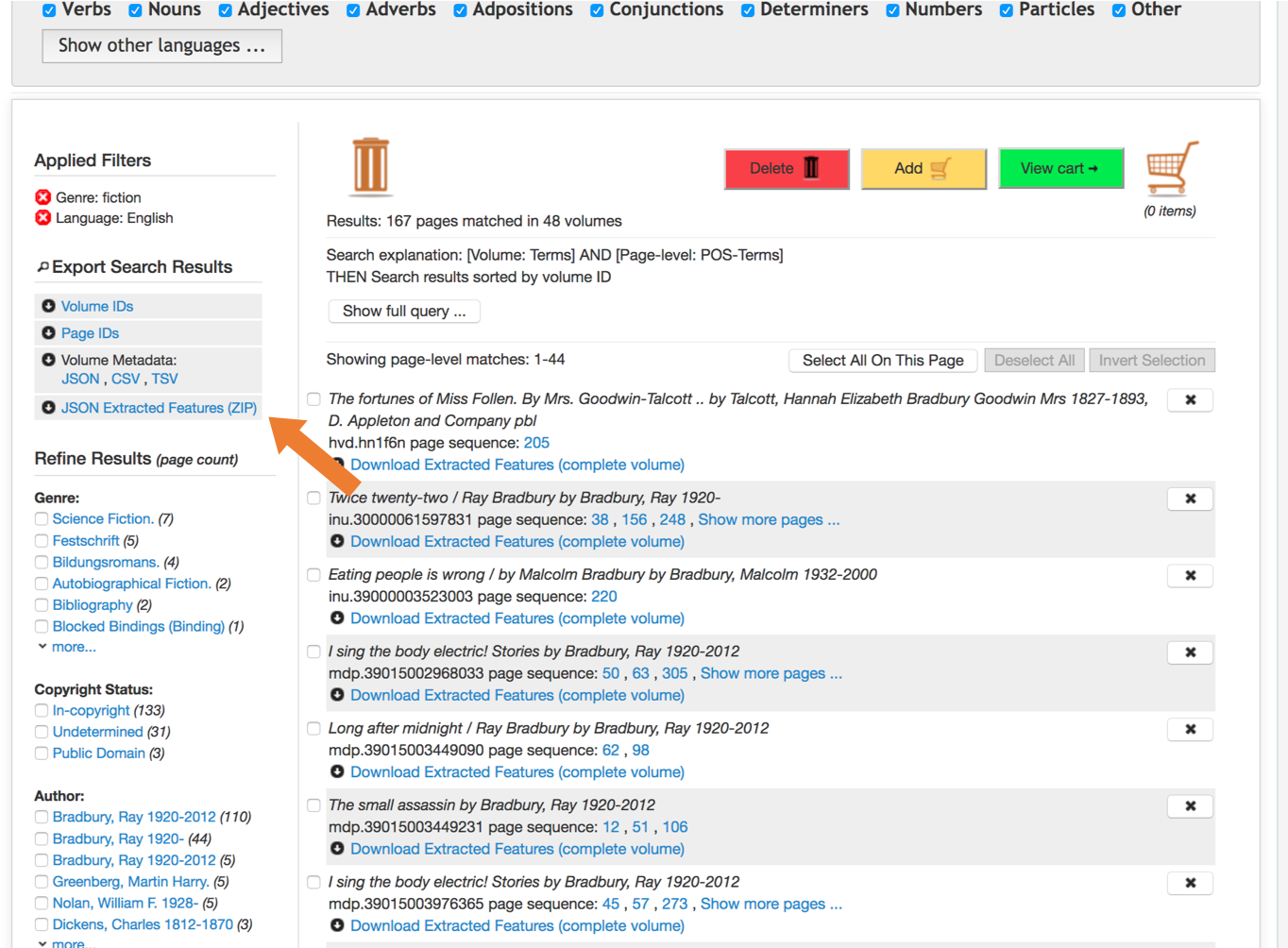
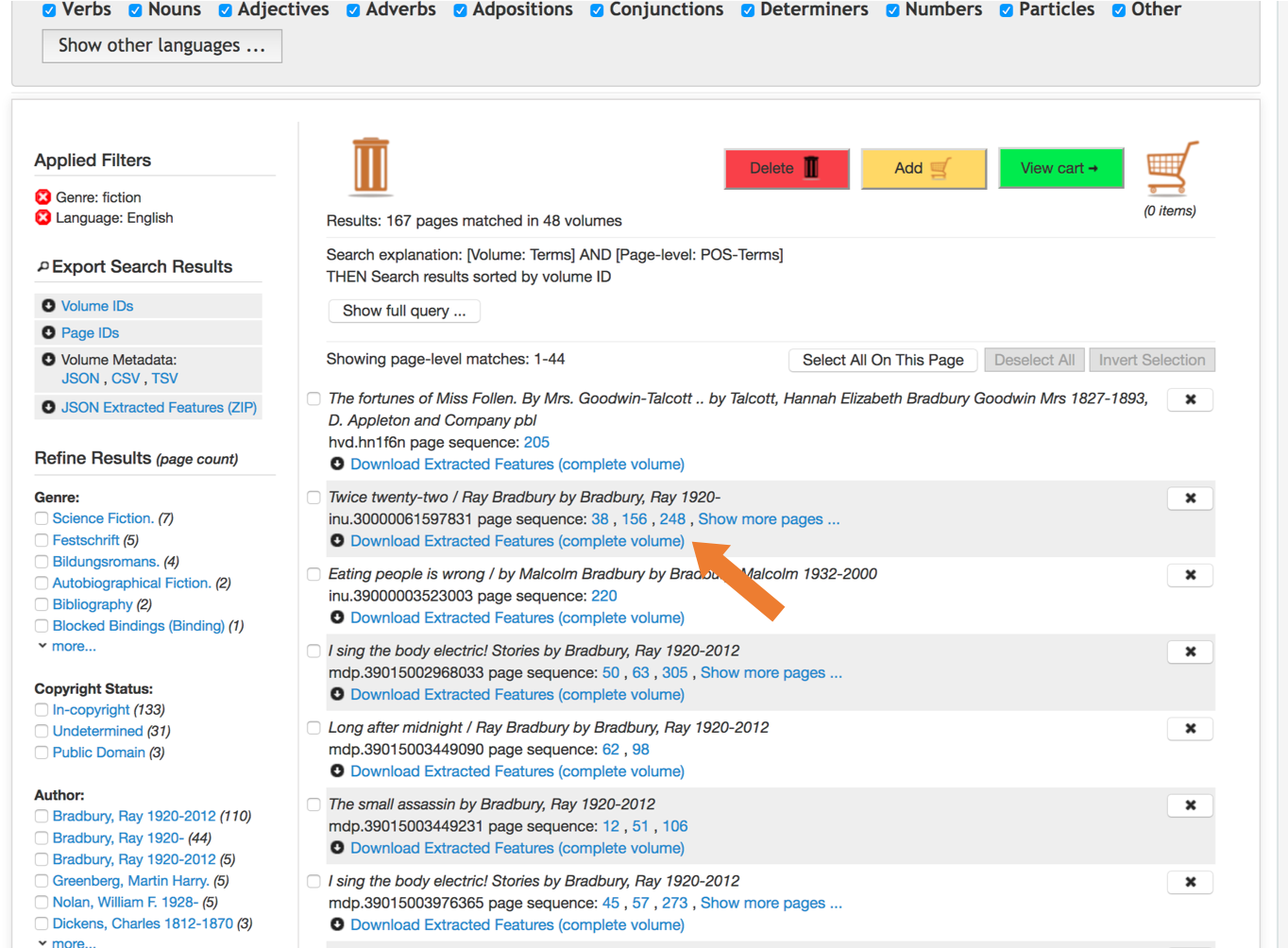
If you'd like to download Extracted Features files for individual volumes, you can click the link "Download Extracted Features (complete volume)" under each volume in the search results. This will download uncompressed Extracted Features for the given volume, in JSON.
Use HTRC EF Download Helper Algorithm
To download the Extracted Features data for a specific workset in HTRC Analytics, there is an algorithm that generates the Rsync download script, the Extracted Features Download Helper. The tool can also be useful if you don’t want to go through the process of determining files paths. Select version 1.5 when you run the algorithm to get the Extracted Features 1.5 version of the files.
The algorithm creates a shell script that you can download and run from your local command line. The file lists the rsync commands for every volume in an HTRC workset. Once you have run the algorithm and downloaded the resulting file, you will run the resulting .sh file.
Go to HTRC Analytics
Navigate to https://analytics.hathitrust.org and log in.
Go to the Worksets page of HTRC Analytics
Click on the 'Worksets' link near the top of the screen. From the list of worksets that appear, choose the one you would like to get Extracted Features for and click on its name.
From the 'Analyze with Algorithm' drop down menu, choose the Extracted Features Download Helper algorithm.
This algorithm generates a script for downloading the feature data files that correspond to your workset.
Execute the Extracted Features Download Helper algorithm
Specify a job name of your choosing. Select Extracted Features 1.0 from the dataset drop down.Then, click the ‘Submit’ button.
Wait until the algorithm has finished and then open the completed job to download
Eventually, the job will complete, and it will move to the "Completed Jobs" section of the page. Click on the link representing the job name to see the results.
From the results page, click the blue button to download the shell script you will use to get the Extracted Features. The file will go wherever downloads typically end up on your machine, often the Downloads folder.
Downloading Extracted Features version 0.2
Download Format
File Format
Sample Files
A sample of 100 extracted feature files is available for download through your browser: sample-EF201801.zip.
Also, thematic collections are available to download: DocSouth_sample_EF201801.zip (87 volumes), EEBO_sample_EF201801.zip (355 volumes), ECCO_sample_EF201801.zip (505 volumes).
Filepaths
The data is stored in a pairtree directory structure, allowing you to infer the location of any file based on its HathiTrust volume identifier. Pairtree format is an efficient directory structure, which is important for HathiTrust-scale data, where the files are placed in directories based on “pairs” of characters in their file names. For example the Extracted Features file for the volume with HathiTrust ID mdp.39015073767769 would be located at:
mdp/pairtreeroot/39/01/50/73/76/69/39015073767769
When you download the files, they will sync in pairtree directory structure, as well.
Download Options
Rsync
Rsync will download each feature file individually, following a pairtree directory structure.
The Rsync module (or alias path) for Extracted Features .2 is data.analytics.hathitrust.org::features-2015.02
If you run the rsync command as written above, without specifying file paths, it will sync all files. Do not do this unless you are prepared to work with the full dataset, which is 1.2 TB. Make sure to include the final period (.) when running your command in order to sync the files to your current directory, or else provide the path to the local directory of your choosing where you would like the files to be synced to.
A full listing of all the files is available from:
rsync -azv data.analytics.hathitrust.org::features-2015.02/listing/file_listing.txt
Users hoping for a more flexible file listing can use rsync's --list-only flag.
To rsync only the files in a given text file:
rsync -av --files-from FILE.TXT data.analytics.hathitrust.org::features-2015.02/.
Use HTRC EF Download Helper Algorithm
To download the Extracted Features data for a specific workset in HTRC Analytics, there is an algorithm that generates the Rsync download script, the Extracted Features Download Helper. The tool can also be useful if you don’t want to go through the process of determining files paths. Select version 0.2 when you run the algorithm to get the Extracted Features 0.2 version of the files.
The algorithm creates a shell script that you can download and run from your local command line. The file lists the rsync commands for every volume in an HTRC workset. Once you have run the algorithm and downloaded the resulting file, you will run the resulting .sh file.
Go to HTRC Analytics
Navigate to https://analytics.hathitrust.org and log in.
Go to the Worksets page of HTRC Analytics
Click on the 'Worksets' link near the top of the screen. From the list of worksets that appear, choose the one you would like to get Extracted Features for and click on its name.
From the 'Analyze with Algorithm' drop down menu, choose the Extracted Features Download Helper algorithm.
This algorithm generates a script for downloading the feature data files that correspond to your workset.
Execute the Extracted Features Download Helper algorithm
Specify a job name of your choosing. Select Extracted Features 0.2 from the dataset selection drop down. Then, click the ‘Submit’ button.
Wait until the algorithm has finished and then open the completed job to download
Eventually, the job will complete, and it will move to the "Completed Jobs" section of the page. Click on the link representing the job name to see the results.
From the results page, click the blue button to download the shell script you will use to get the Extracted Features. The file will go wherever downloads typically end up on your machine, often the Downloads folder.